はじめに
近年、生成AIの活用が急速に広がっており、
文章生成、プログラム作成、要約、ファクトチェックなど
様々な業務で利用されるようになっています。
しかし、企業で生成AIを活用しようとすると、
次のような課題に直面することが多くあります。
- 社内ルールや業務マニュアルをもとに回答してほしい
- 社内FAQなどの独自ナレッジをAIに回答させたい
- 公開情報ではなく社内ドキュメントを参照した回答を得たい
ChatGPTなどの汎用AIは、基本的には公開情報をもとに回答を生成するため、企業固有のナレッジを直接参照することはできません。
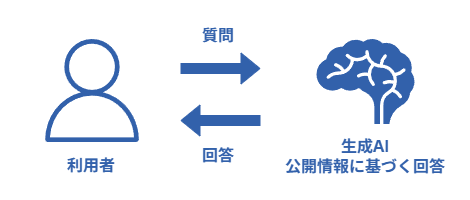
この課題を解決する方法として注目されているのが
RAG(Retrieval-Augmented Generation:検索拡張生成) です。
RAGでは、ユーザーの質問に対して関連するドキュメントを検索し、
その検索結果をAIのプロンプトに追加することで回答を生成します。
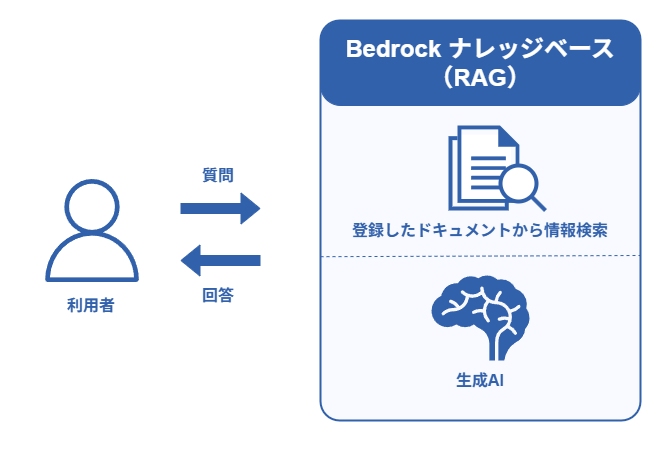
本記事では、AWSの Amazon Bedrock Knowledge Bases を利用して、
社内ドキュメントをもとに回答する生成AI APIを構築する方法を紹介します。
この記事では以下の内容を学ぶことができます。
- Bedrock Knowledge Baseを利用したRAG構成
- 社内ドキュメントを利用した生成AI APIの構築
- OpenSearch Serverlessを利用したベクトル検索
- RAGシステム設計のポイント
また、実際に動作するコードはGitHubで公開しているため、すぐにデプロイして試すことができます。
システム構成
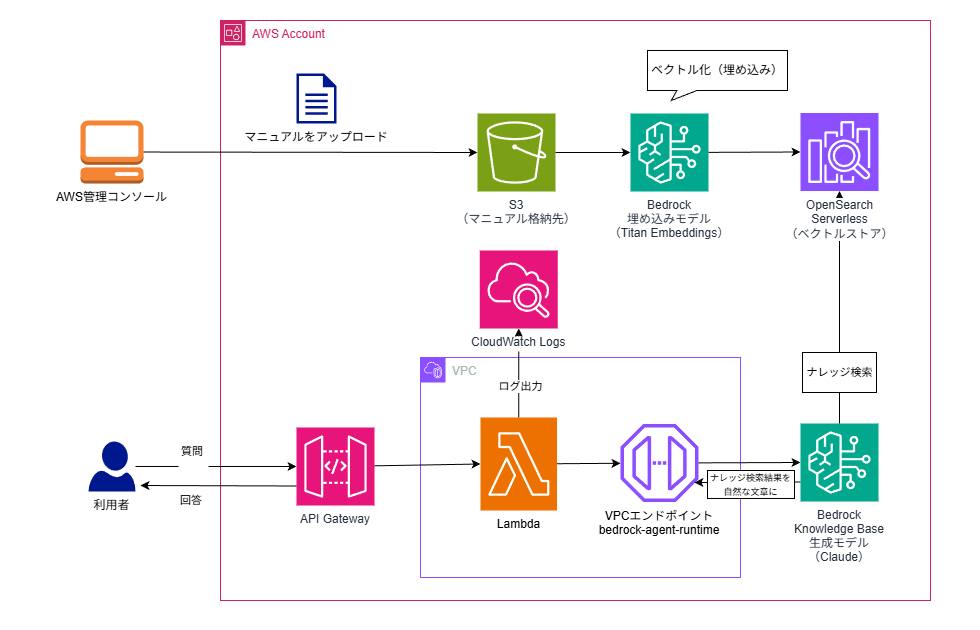
今回構築するシステムの構成は以下です。
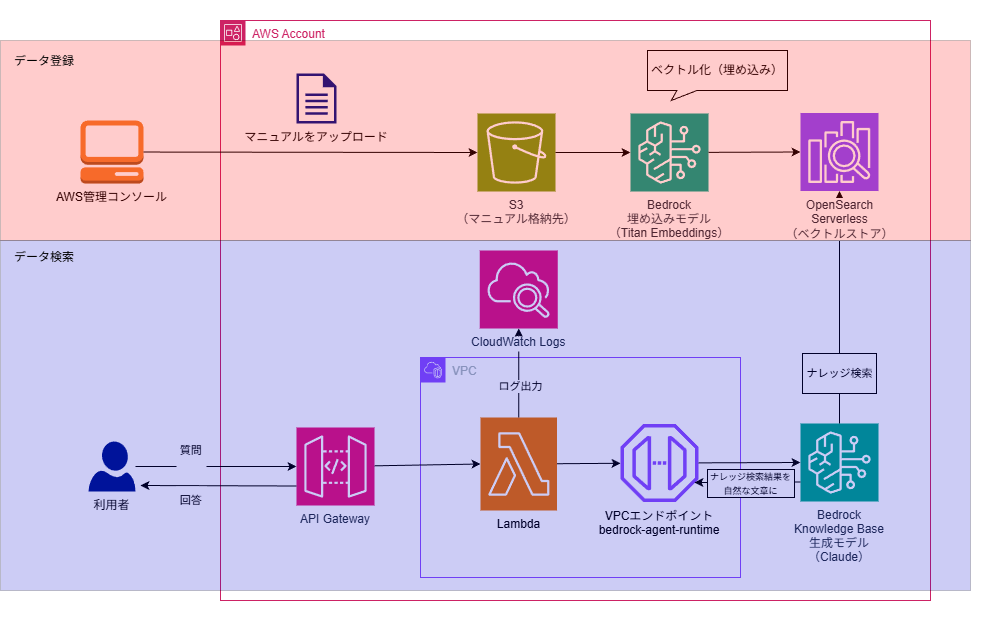
上側(赤色部分)はナレッジ登録処理で利用、下側(青色部分)は検索処理で利用するサービスです。
① ナレッジ登録処理
- S3にドキュメントを保存
- Bedrock Knowledge Baseがドキュメントを読み込み
- Embeddingモデルでベクトル化
- OpenSearch Serverlessにベクトルを保存
② 検索処理
- API Gateway経由で質問を受信
- Lambda関数がKnowledge Baseへ問い合わせ
- OpenSearch Serverlessで類似ドキュメント検索
- 生成AIが回答生成
サービス選定
今回の構成では以下のサービスを利用しています。
| サービス | 用途 |
|---|---|
| Amazon Bedrock | 生成AIモデルの利用 |
| Bedrock Knowledge Base | RAG構成の管理 |
| OpenSearch Serverless | ベクトル検索 |
| API Gateway | API公開 |
| Lambda | API処理 |
| S3 | ドキュメント保存 |
OpenSearch Serverlessを採用した理由
Bedrock Knowledge Baseでは、ベクトルデータストアとして複数のサービスを利用できます。
- OpenSearch Serverless
- Amazon Aurora PostgreSQL Serverless(pgvector)
- Amazon Neptune Analytics(Graph RAG)
- Amazon S3 Vectors
それぞれ特徴が異なります。
- OpenSearch Serverless
検索エンジンとして設計されており、高速なベクトル検索と全文検索を組み合わせることができます。 - Amazon Aurora PostgreSQL Serverless
pgvector拡張を利用したベクトル検索が可能ですが、データベースとしての用途が中心であり、大量データの検索用途ではチューニングが必要になる場合があります。 - Amazon Neptune Analytics
グラフ構造を活用したGraph RAGに適していますが、一般的なドキュメント検索用途ではやや用途が限定されます。 - Amazon S3 Vectors
低コストでシンプルなベクトルストレージですが、検索エンジンとしての機能は限定的です。
今回のシステムでは「ドキュメント検索」を主目的としているため、以下の理由から OpenSearch Serverless を採用しました。
- ベクトル検索と全文検索を組み合わせた高速検索が可能
- 検索エンジンとして設計されており、大量ドキュメントの検索に適している
- フルマネージドのため、クラスタ管理やスケーリングを意識せず利用できる
RAGシステムでは、関連ドキュメントを正確かつ高速に取得することが回答品質に大きく影響します。
そのため、本記事では検索用途に最適化されたOpenSearch Serverlessをベクトルストアとして採用しています。
RAGシステム設計のポイント
RAG(Retrieval-Augmented Generation)では単にAIを呼び出すだけではなく、検索精度を高めるための設計が重要になります。
チャンク戦略
RAGでは、ドキュメント全体をそのまま検索するのではなく、ドキュメントを一定の単位に分割(チャンク化)してからベクトル化します。
このチャンクの分割方法は検索精度に大きく影響するため、「チャンク戦略」として設計することが重要です。
本記事では、ドキュメントを約500トークン単位で分割するチャンク戦略を採用しています。
また、分割は可能な限り段落単位で行うようにしています。
500トークン程度のチャンクサイズは、RAGシステムにおいて以下の理由からバランスがよいとされています。
- 1つのチャンクに十分な文脈を保持できる
- 検索時に関連性の高い情報を取得しやすい
- LLMに渡すコンテキストサイズを抑えられる
- 一般的なRAG実装で採用されることが多いサイズ帯(400〜800トークン)に含まれる
チャンクサイズが小さすぎる場合、情報が断片化されて文脈が失われる可能性があります。
一方でチャンクが大きすぎる場合、検索結果に無関係な情報が含まれやすくなり、回答精度が低下することがあります。
そのため、本記事では文脈の保持と検索精度のバランスを考慮し、500トークン程度のチャンクサイズを採用しています。
なお、チャンク戦略には他にもいくつかの方法があります。
- 固定サイズのチャンキング(Fixed-size chunking)
一定トークン数で機械的に分割する方法で、実装がシンプルなため多くのRAGシステムで利用されています。 - 階層型チャンキング(Hierarchical chunking)
文章の段落や見出しなど、ドキュメント構造を基準に分割する方法です。文脈を保ちやすく、技術文書やマニュアルとの相性が良いのが特徴です。 - セマンティックチャンキング(Semantic chunking)
文章の意味的なまとまりを分析して分割する方法です。検索精度を高めることができますが、前処理のコストが高くなる場合があります。
実際のRAGシステムでは、ドキュメント構造や検索クエリの傾向によって最適なチャンク戦略は変わるため、検索精度を確認しながら調整することが重要です。
Embeddingモデル
ドキュメント検索ではテキストをベクトル化します。
本記事では以下のモデルを利用しています。
amazon.titan-embed-text-v2:0
Embeddingモデルは検索精度に大きく影響するため、用途に応じて選択する必要があります。
検索件数(TopK)
RAGでは検索されたドキュメントをAIのプロンプトに含めます。
- TopKが少ない → 情報不足
- TopKが多い → コスト増加
適切な検索件数の設定が重要になります。
ハルシネーション対策
生成AIでは、事実ではない回答(ハルシネーション)が発生する可能性があります。
対策として以下が重要です。
- 検索結果をプロンプトに含める
- 回答の参照元を表示する
- 回答できない場合の処理を定義する
本システムでは、検索されたドキュメント情報をCloudWatchログに出力しています。
セキュリティ設計
本構成では以下のセキュリティ設計を行っています。
- VPC内からBedrockへアクセス
- VPCエンドポイント経由で通信
- インターネットを経由しない構成
これにより、生成AI処理を 閉域ネットワーク内で実行できる構成になっています。
費用
主な費用は以下です。
| サービス | 料金 |
|---|---|
| API Gateway | 無料枠内 |
| Lambda | 無料枠内 |
| S3 | データ量に応じて課金 |
| Bedrock | トークン課金 |
| OpenSearch Serverless | 約0.67 USD / 時間(最小構成) |
OpenSearch Serverlessは常時課金されるため、ハンズオン後は削除することを推奨します。
構築手順
以下のリポジトリをクローンします。(GitHub ページ)
git clone https://github.com/TeTeTe-Jack/aws-handson-knowledgebase-api.git
cd aws-handson-knowledgebase-apicfn/parameters.json.templateからcfn/parameters.jsonファイルを作成します。
以下のパラメータを修正してください
[
{
"ParameterKey": "Prefix",
"ParameterValue": "my-kb-project" // ★リソースのプレフィックス値
},
{
"ParameterKey": "LambdaSourceBucketName",
"ParameterValue": "my-kb-deploy-bucket" // ★Lambdaのソースを格納するバケット
},
{
"ParameterKey": "LambdaSourceKey",
"ParameterValue": "kb-api/kb-api.zip" // ★Lambdaのソースを格納先のオブジェクトキー
},
{
"ParameterKey": "KnowledgeBaseBucketName",
"ParameterValue": "my-kb-manual-bucket" // ★ナレッジベースに登録するドキュメントが格納されたバケット名
},
{
"ParameterKey": "KnowledgeBasePrefix",
"ParameterValue": "manual/" // ★ナレッジベースに登録するドキュメントが格納先のプレフィックス
},
{
"ParameterKey": "EmbeddingModel",
"ParameterValue": "amazon.titan-embed-text-v2:0" // 固定
},
{
"ParameterKey": "GenerationModelIdOrInferenceProfile",
"ParameterValue": "global.anthropic.claude-haiku-4-5-20251001-v1:0" // 固定(別のプロファイルを使う場合は修正)
},
{
"ParameterKey": "AvailabilityZoneCount",
"ParameterValue": "1" // AZ数(初期値は1AZ)
},
{
"ParameterKey": "OpenSearchServerlessMultiAZMode",
"ParameterValue": "OFF" // OpenSearch のMultiAZ対応(初期値はOFF=シングルAZ)
},
{
"ParameterKey": "LogRetentionInDays",
"ParameterValue": "7" // ログの保持期間日数
}
]依存パッケージをインストールします。
npm installLambdaコードをビルドします。
npm run zipCloudFormationでリソースをデプロイします。
npm run deployナレッジベースを同期します。
npm run sync動作確認
APIを実行します。ドキュメントの内容に応じてテストコマンドを修正してください。
- テストコマンド:scripts/test.ts
- 修正箇所:main() 関数のqueryApi(“質問”)の質問内容
APIの実行は以下からできます。
npm run testナレッジベースに登録したドキュメントをもとに回答が生成されます。
結果例
AWSの認定資格のドキュメントを登録して試してみます。
2025年12月16日から受験可能になった、「AWS Certified Generative AI Developer – Professional」のドキュメントは登録していません。
まずはどの資格から?
全体的な質問をしてみます。
質問:AWSをこれから使い始めます。まずはどの資格から取得するのがいいですか?
レスポンス
{
"message": "AWSをこれから使い始める場合は、AWS Certified Cloud Practitioner(CLF-C02)の取得をお勧めします。\n\nこの認定は、AWS クラウドの設計、実装、オペレーションの経験が6か月以下の受験者を対象としており、キャリアの初期段階 にある人や、AWS クラウドで役割を担う人々と一緒に仕事をしている人が対象です。\n\n学習対象範囲としては、AWSクラウド のコンセプト、セキュリティとコンプライアンス、主要なサービス、クラウドエコノミクスなど、基礎的な知識をカバーしています。これらは、その後のより専門的なAWS資格取得への基盤となります。"
}資格についての質問
特定の資格についての質問をしてみます。
質問:SAAの正式名称は?
{
"message": "SAAの正式名称は「AWS Certified Solutions Architect - Associate (SAA-C03)」です。"
}RAGに登録されていない資格
ドキュメント登録をしていない内容で聞いてみます。
質問:AWS Certified Generative AI Developer – Professionalの試験範囲を教えてください。
{
"message": "申し訳ありませんが、提供いただいた検索結果にはAWS Certified Generative AI Developer - Professionalの試験ガイドが含まれていません。検索結果には、AWS Certified Data Engineer - Associate (DEA-C01)、AWS Certified Cloud Practitioner (CLF-C02)、AWS Certified Developer - Associate (DVA-C02)、AWS Certified AI Practitioner (AIF-C01)の 試験ガイドが含まれていますが、ご質問の試験については情報がございません。\n\nAWS Certified Generative AI Developer - Professionalの試験範囲についての正確な情報を得るには、AWSの公式認定ページで該当する試験ガイドを確認されることを お勧めします。"
}
どれもいい感じに回答できてますね!
ドキュメントとして持っていない情報についても無理やり回答せずに情報がない旨の回答ができています。
API出力には含めていませんが、CloudWatchログに回答生成時に参照されたドキュメントを確認できます。
リソースの削除
動作確認後は不要な課金を防ぐため、
以下のコマンドでリソースを削除してください。(特にOpenSearch Serverlessは時間課金+従量課金のためご注意ください。)
npm run deleteまとめ
Amazon Bedrock Knowledge Baseを利用することで、社内ドキュメントを活用した生成AIシステムを比較的簡単に構築できます。
本記事で紹介した構成では以下を実現しています。
- 社内ドキュメントを利用したRAG
- OpenSearch Serverlessによるベクトル検索
- APIとして利用可能な生成AI
- 閉域ネットワークでのセキュアな構成
生成AIは単体ではなく、既存システムやドキュメントと組み合わせることで真価を発揮します。
ぜひ本記事を参考に、業務に合わせたRAGシステムの構築に挑戦してみてください。

