はじめに
「AWS Certified AI Practitioner(AIF)」の合格したので、その学習ポイントを紹介します。
人工知能(AI)や機械学習(ML)について知識がなく、資格の取得のための勉強のハードルが高いと思っている方は多いのではないでしょうか?
実際、私もサンプルの問題を解いてみて、AIやMLの専門用語の知識やAWSのAI関連のサービス(特にSageMaker)の知識を問われることが多く、他の資格取得で習得した知識とマッチせず苦労しました。
そこで本記事では、私自身の経験をもとに、AIやMLの知識がない方でも合格できるよう、学習ポイントをわかりやすく紹介していきます。
この記事は以下の方におすすめです。
- ✅AWS Certified AI Practitioner(AIF)取得に向けて勉強を始めたい方
- ✅AWSでAIを利用する上で基本的な知識を学びたい方
- ✅AWSの知識はあるけどAIの知識に自信のない方
記事の内容としては以下になります。
- 基本用語
- 機械学習のライフサイクル
- AWSのAI・ML関連サービス
- AWSの基本サービス
AWS Certified AI Practitioner(AIF)について
試験概要についてすでにご存じの方は読み飛ばしてください。
認定資格について
この資格を通じて、以下のような知識を習得できます。
- ✅ AI・ML・生成AIに関する基本的な理論や用語
- ✅ AWSのAI関連サービス(SageMaker、Bedrockなど)の概要と使い方
- ✅ AIサービスをセキュアに利用するためのベストプラクティス
AI/MLに馴染みがない方でも、実務でAIを扱う入り口として非常に有効な資格です。
AWSの利用が未経験の方は、まずは「AWS Certified Cloud Practitioner」からの学習がおすすめです。
AIFではIAMや責任共有モデル、各サービスの基本機能なども問われるため、先に基礎を学んでおくとスムーズに学習できます。
以下はAWS Certified AI Practitioner(AIF)の試験概要です。
| 項目 | 詳細 |
|---|---|
| 試験時間 | 90分 |
| 合格ライン | 700点(100~1,000点中) |
| 問題数 | 65問(選択式・複数選択式・並び替え・内容一致・ケーススタディ) |
| 受験費用 | 15,000円(2025/7/5時点) |
詳細や最新情報はAIFの試験ガイドを参照してください。
受験前のレベルについて
簡単に私のAWSの業務経験、AIの知識、保有資格を紹介します。
AWSについてはそれなりの知識・業務経験はありますが、AIについては生成AIを使ったことが程度のスキルで、一般的なAIの知識については初心者です。
AWSの経験:AWSを使ったサーバレスWebサービスのインフラやアプリ設計業務(3年)
AIの経験:AIについては、個人開発でChatGPTを使い、コード生成やプロンプト調整を行った程度の経験です。
一方で、一般的なAIや機械学習の理論には不慣れな状態からのスタートでした。
保有資格:
| 資格 | 取得月 |
|---|---|
| AWS Certified Cloud Practitioner | 2022/6 |
| AWS Certified Solutions Architect – Associate | 2023/6 |
| AWS Certified Solutions Architect – Professional | 2024/3 |
| AWS Certified Developer – Associate | 2024/9 |
| AWS Certified Security – Specialty | 2024/12 |
| AWS Certified DevOps Engineer -Professional | 2025/3 |
基本用語
カテゴリごとに用語をまとめました。頭の中に入れておくとスムーズに問題文を理解できます。頑張って覚えましょう!
機械学習の基本用語
| 用語 | 説明 |
|---|---|
| モデル (Model) |
入力データからルールを学び、予測や判断を行う仕組み。 学習の結果できあがるもの。 |
| トレーニング (Training) |
モデルにデータを与えて学習させること。 これにより予測精度が向上する。 |
| 推論 (Inference) |
学習済みのモデルに新しいデータを入力して、 予測や判断をさせること。 |
| データセット | モデルの学習や評価に使うデータの集まり。 複数のデータ(例:画像や数値)からなる。 |
| 学習データ | モデルをトレーニングするためのデータ。 正解付きのものが使われることが多い。 |
| テストデータ | 学習後のモデルがどれだけ正しく動くかを評価するためのデータ。 |
| 正解率 (Accuracy) |
モデルの予測がどれだけ正しかったかを示す割合。高いほど良い。 |
| ラベル | 正解を示す情報。分類や予測の「答え」となるデータ。 |
| 学習 (Learning) |
モデルがデータからパターンを見つけ、 予測できるようになるプロセス。 |
| 評価 (Evaluation) |
モデルの良し悪しを判断すること。 テストデータなどを使って行う。 |
機械学習の種類
| 用語 | 説明 |
|---|---|
| 教師あり学習 | 「入力データ」と「正解ラベル」がセットになったデータをもとに、 未知のデータに対して正しい出力を予測するモデルを学習させる手法。 利用例)スパムメール判定・画像認識 |
| 教師なし学習 | 「正解ラベルのないデータ」から構造やパターンを見つけ出す学習手法。 利用例)データの分類・製品の異常検知 |
| 強化学習 | 「環境」と「エージェント」の相互作用を通じて、 「報酬を最大化する行動方針(ポリシー)」を学習する手法。 利用例)ゲームAI・広告表示の最適化 |
推論の種類
| 推論の種類 | 概要 | 特徴 |
|---|---|---|
| バッチ推論 | 複数の入力データをまとめて 一括処理する方式 |
処理効率が高いが リアルタイム性は低い |
| リアルタイム推論 | APIなどを通じてリクエストごとに 即座に推論を返す |
応答速度が速く ユーザーとの対話に適す |
| 非同期推論 | リクエスト送信後すぐに応答せず 推論完了後に結果を返す仕組み |
リアルタイム性は不要だが 大規模処理に対応 |
学習モデルの評価指標
分類(ラベリング)
分類の評価指標について一覧化しました。
| 指標名 | 概要 |
|---|---|
| 混同行列 (Confusion Matrix) |
分類モデルの予測結果と実際の正解を比較するための表 |
| 正解率 (Accuracy) |
正しく分類された割合 |
| 適合率 (Precision) |
陽性と予測した中で実際に陽性だった割合 |
| 再現率 (Recall) |
実際に陽性の中で正しく陽性と予測できた割合 |
| F1スコア | 「適合率(Precision)」と「再現率(Recall)」のバランスをとった指標 どちらか一方だけが高いときに過剰評価されることを防ぐ 特に、データに偏りがある場合(例:病気の人が少数)に有効 |
混同行列・F1スコア
| 予測結果 | |||
|---|---|---|---|
| 陽性 | 陰性 | ||
| 実際の値 | 陽性 | TP(真陽性) 正しく陽性と予測 |
FN(偽陰性) 実際は陽性だが陰性と予測 |
| 陰性 | FP(偽陽性) 実際は陰性だが陽性と予測 |
TN(真陰性) 正しく陰性と予測 |
|
各種計算式は以下です。
- 正解率(Accuracy)=(TP+TN)/(TP + TN + FP + FN)
- 適合率(Precision)=TP/(TP+FP)
- 再現率(Recall)=TP/(TP+FN)
- F1スコア=2×Precision×Recall/(Precision+Recall)
データに偏りがある場合、正解率(Accuracy)では適切な評価ができません。
F1スコアで評価するのがいいです。
以下F1スコアと正解率(Accuracy)の評価の例です。
ある病気の診断を行うAIモデルを想定します。
- 対象者:1,000人
- 実際に病気の人(陽性):10人
- 健康な人(陰性):990人
◆モデルAの予測結果(すべて陰性と予測)
| 予測:陽性 | 予測:陰性 | |
|---|---|---|
| 実際:陽性 | 0(TP) | 10(FN) |
| 実際:陰性 | 0(FP) | 990(TN) |
- Accuracy(正解率): 99.0%
- Precision(適合率): 0
- Recall(再現率): 0
- F1スコア: 0
見た目の正解率は高いが、病気の人を1人も見つけられていない「使えないモデル」。
◆モデルBの予測結果(陽性20人中、実際の病気10人)
| 予測:陽性 | 予測:陰性 | |
|---|---|---|
| 実際:陽性 | 10(TP) | 0(FN) |
| 実際:陰性 | 10(FP) | 980(TN) |
- Accuracy(正解率): 99.0%
- Precision(適合率): 0.5
- Recall(再現率): 1.0
- F1スコア: 0.666
正解率は同じでも、病気の人をしっかり見つけられており、F1スコアが高い。
データに偏りがある場合、Accuracy(正解率)だけでは正確な評価ができません。
F1スコアは、Precision(適合率)とRecall(再現率)のバランスを取った指標で、
少数クラス(この例では「病気」)を適切に評価できるモデルかどうかを判断するのに有効です。
回帰(数値の予測)
回帰で使われる主な評価指標は以下です。
| 指標名 | 概要 |
|---|---|
| 平均二乗誤差 (MSE) |
誤差(予測値と正解の差)を2乗して平均したもの。外れ値の影響を受けやすい |
| 平均絶対誤差 (MAE) |
誤差の絶対値の平均。外れ値の影響がMSEより小さい |
| 決定係数 (R²スコア) |
予測がどれだけうまく実測値を説明できているか 数式は以下 R² = 1 − (残差平方和 / 全体平方和) ・1に近いほど良い ・0は平均値で予測するのと同じ精度 ・<0は平均値で予測する精度より悪い |
住宅価格シミュレーションの例としてあげると以下のようになります。
| データ | 実際の価格 (万円) | 予測価格 (万円) | 誤差 | 誤差² | |誤差| |
|---|---|---|---|---|---|
| A | 3,000 | 2,800 | -200 | 40,000 | 200 |
| B | 2,500 | 2,600 | 100 | 10,000 | 100 |
| C | 4,000 | 4,100 | 100 | 10,000 | 100 |
- MSE:(40,000 + 10,000 + 10,000) / 3 = 20,000
- MAE:(200 + 100 + 100) / 3 = 133.33
- R²: 0.873(計算は省略)
生成AIの基本的な用語
基本用語
| 用語 | 説明 |
|---|---|
| 生成AI (Generative AI) |
テキスト・画像・音声・コードなどの新しいコンテンツを生成するAI 大規模な基盤モデルにより実現される |
| 基盤モデル (Foundation Model) |
多様なタスクに対応できるように 大規模データで事前学習された汎用モデル |
| 大規模言語モデル (LLM) |
自然言語処理に特化した基盤モデル テキスト生成・要約・翻訳などに利用される。 |
| プロンプト (Prompt) |
生成AIに指示を与える入力文 プロンプトの工夫により生成される出力の品質が変わる |
| RAG (Retrieval-Augmented Generation) |
外部のナレッジベースから情報を検索し モデルに補足する手法 FAQ・社内QAなどに活用される |
| ファインチューニング | 事前学習済みの基盤モデルを、 特定のデータで再学習しカスタマイズする手法。 |
| トークン | 生成AIが処理する最小単位の文字列 単語や句読点、サブワード単位などに分割される 課金やモデル制限もトークン単位で行われる |
| チャンク | 大きな文章やドキュメントを一定のサイズに分割した部分 RAGや検索向けに分割し効率的に処理するために使う |
| 埋め込み (Embedding) |
単語や文書をベクトル空間に変換する手法 文の意味や関連性を数値的に表現し 検索・分類・クラスタリングに活用 |
| ベクターマルチモーダルモデル | テキスト・画像・音声など複数の種類のデータを ベクトルとして統合処理できるモデル |
| 拡散モデル (Diffusion Model) |
画像生成などで使われる生成モデル ノイズを加えていき、 逆にノイズを除去して元データを生成する仕組み |
プロンプトの種類
| 用語 | 説明 |
|---|---|
| シングルショット (One-shot) |
1つの例だけを提示してAIに学習させるプロンプト設計手法 ゼロショットとフューショットの中間にあたる |
| フューショット (Few-shot) |
2〜数件程度の例を提示して AIに出力の形式や内容を理解させるプロンプト設計手法 |
| 思考の連鎖 (Chain of Thought) |
推論ステップを明示的に書かせることで 複雑な問題を段階的に解決させる手法 例:「まずAを計算し、次にBを求める…」 |
| プロンプトテンプレート | 入力文の構造を一定のフォーマットにし 再利用性を高めたプロンプト 例:「あなたは〇〇の専門家です。以下の文章を要約してください:{input}」 |
プロンプトのセキュリティ
| 用語 | 説明 |
|---|---|
| 露出 (Exposure) |
LLMが学習時に取り込んだ個人情報や機密情報を 出力として意図せず生成してしまう現象 |
| ポイズニング (Poisoning) |
悪意のあるデータを学習に含めることで モデルの出力に偏りや誤りを意図的に発生させる攻撃手法 |
| ハイジャック (Hijack) |
正規のプロンプトに対して悪意ある入力を混入し モデルの振る舞いを乗っ取るような攻撃 |
| ジェイルブレイク (Jailbreak) |
モデルの安全対策をバイパスして 禁止された応答を引き出す入力の設計手法 例:「物語として教えて」「ふざけた質問として回答して」など |
生成AIの評価指標
| 用語 | 説明 |
|---|---|
| ROUGE (Recall-Oriented Understudy for Gisting Evaluation) |
生成テキストと正解テキストの間の類似性(リコール中心)を評価する指標 主に要約タスクで利用 |
| BLEU (Bilingual Evaluation Understudy) |
生成文と参照文のn-gramの一致率を評価する指標 機械翻訳の品質評価でよく用いられる |
| BERTScore | BERTなどの事前学習言語モデルを使って 意味的な類似性を評価する指標 文の意味理解に基づいた比較が可能 |
機械学習のライフサイクル
機械学習のライフサイクルのイメージです。機械学習と聞くとモデルの学習やモデルの評価を想像することが多いと思います。
実際は法的なコンプライアンスの課題は要件定義のタイミングでクリアしておくべきですし、モデルを継続的に改善するといったフェーズがあることを押さえておいてください。
以下の図は機械学習のライフサイクルの一例になります。
「継続的な改善」が「データ収集」に戻っていますが、改善内容によって戻るフェーズが変わりますのでご注意ください。
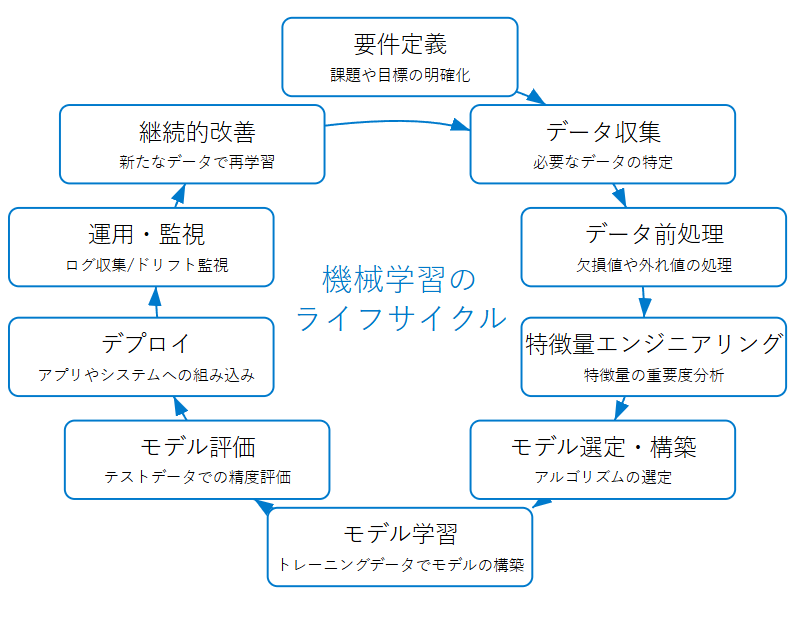
各フェーズでの実施することを表でまとめました。
| フェーズ名 | 実施すること |
|---|---|
| ① 要件定義 | ・ビジネス課題や目標の明確化 ・機械学習で解決できるかの検討 ・成功基準(評価指標)の設定 |
| ② データ収集 | ・必要なデータの特定 ・社内システムや外部ソースからのデータ取得 ・APIやログなどの収集設定 |
| ③ データ前処理 | ・欠損値や外れ値の処理 ・データ形式の変換(カテゴリ変数→数値など) ・正規化や標準化などのスケーリング |
| ④ 特徴量エンジニアリング | ・特徴量の重要度分析 ・予測に役立つ変数の作成・選定 ・次元削減などの処理 |
| ⑤ モデル選定・構築 | ・アルゴリズムの選定 (例:決定木、SVM、ニューラルネットワーク) ・学習・検証用データの分割 |
| ⑥ モデル学習 | ・トレーニングデータを使ってモデルの構築 ・ハイパーパラメータの調整 ・精度・過学習の確認 |
| ⑦ モデル評価 | ・テストデータでの精度評価 ・混同行列、F1スコアなどの指標確認 ・ビジネス目標との比較 |
| ⑧ デプロイ | ・モデルをAPIとして公開 ・アプリやシステムへの組み込み ・リアルタイム/バッチ推論環境の構築 |
| ⑨ 運用・監視 | ・推論ログの収集 ・モデルの精度劣化(ドリフト)の監視 ・再学習の必要性の判断 |
| ⑩ 継続的改善 | ・新たなデータでモデルを再学習(リトレーニング) ・改善案の評価と反映 ・MLOpsによる自動化の検討 |
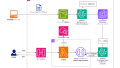
AWSのAI・ML関連サービス
以下の画像を頭の中に入れておくとよいです。こちらの画像をベースによく利用するAI・ML関連サービスをします。
※MLフレームワークとインフラストラクチャについてはAWS範囲外になるので説明を省略します。
 (出典:AWS の主要な AI/ML サービスをグラレコで解説)
(出典:AWS の主要な AI/ML サービスをグラレコで解説)
AIサービス
| カテゴリ | サービス名 | 特徴 |
|---|---|---|
| 画像 | Rekognition | 画像・映像内の物体を検出しラベリングする |
| 音声 | Polly | テキストを読み上げる自然な音声を生成 |
| Transcribe | 音声から文字起こしする | |
| テキスト | Comprehend | テキストの内容を感情分析する |
| Translate | テキストを翻訳する | |
| Textract | OCR。画像/pdf/構造化されたデータからテキスト抽出する | |
| 検索 | Knowledge base | ドキュメント検索する。 (画像内にはありませんが、追加しています) |
| Kendra | ドキュメント検索する。 Knowledge baseより対応範囲が広いが費用は高い |
|
| チャットボット | Lex | AIチャットボット |
| レコメンド | Personalize | ユーザごとにおすすめアイテムの提示 |
MLサービス(SageMaker)
SageMakerの主要サービスについては覚えておきましょう。
データ準備関連
| サービス名 | 概要 |
|---|---|
| SageMaker Ground Truth | ラベル付け済みデータの作成を支援 |
| SageMaker Data Wrangler | GUIベースでデータ前処理を一括管理できるツール |
| SageMaker Feature Store | 特徴量の登録・取得・共有が可能なデータベース |
| SageMaker Canvas | ノーコードでの予測モデル作成が可能な ビジネスユーザー向けツール コーディングスキルがなくても利用可能 短期間でリリースが可能 |
モデル構築・学習
| サービス名 | 概要 |
|---|---|
| SageMaker Studio | 機械学習の開発・実験・デプロイを一元管理できるIDE |
| SageMaker Studio Lab | 無料で使えるJupyterベースのクラウド環境 |
| SageMaker Training | 分散学習やマネージドなトレーニングジョブの実行が可能 |
| SageMaker Debugger | トレーニング中のモデル挙動を可視化・解析するツール |
公平性・説明性
| サービス名 | 概要 |
|---|---|
| SageMaker Clarify | バイアス検出や説明可能性の評価を支援するツール 評価レポート出力できる |
推論・デプロイ
| サービス名 | 概要 |
|---|---|
| SageMaker Real-time Inference | エンドポイントを通じたリアルタイム予測API |
| SageMaker Batch Transform | 大量のデータに対して一括推論を行う処理 |
| SageMaker Asynchronous Inference | リクエストに非同期で応答する推論方式 |
| SageMaker Serverless Inference | インフラ管理不要で軽量な推論を行うサーバレス形式 |
MLOps・継続的運用
| サービス名 | 概要 |
|---|---|
| SageMaker Pipelines | MLワークフローの自動化・管理を行うCI/CDパイプライン機能 |
| SageMaker Model Registry | モデルのバージョン管理と承認フローを提供 |
| SageMaker Model Monitor | 本番環境のモデル精度・データドリフトを監視 |
| SageMaker Model Cards | モデルの目的・倫理・公平性などを文書化するためのツール |
生成AI・事前学習モデル
| サービス名 | 概要 |
|---|---|
| SageMaker JumpStart | 事前学習済みモデルやソリューションテンプレートの提供 |
MLサービス(Bedrock)
AWSの生成AIサービスにBedrockがあります。各AI企業の基盤モデル(FM:Foundation Model)を利用することができます。
基盤モデルの選定と活用
生成AIを活用するには、用途に適した基盤モデル(Foundation Model)を選定することが重要です。
AWSではAmazon Bedrockを通じて複数の基盤モデルプロバイダ(Anthropic、Meta、AI21 Labsなど)を利用でき、モデルごとに得意分野や仕様が異なります。
推論パラメータ
モデルの出力は、以下のような推論パラメータによって制御できます。
- 温度(Temperature):値を高くすると多様な出力、低くすると一貫性のある出力。
- 最大トークン数:レスポンスの長さを制限。適切に設定することでコストも抑制可能。
- Top-p(Nucleus sampling):出力候補の確率上位の範囲内からランダムに選ぶ。
検索拡張生成(RAG)
RAG(Retrieval-Augmented Generation)は、基盤モデルが外部データベースから情報を取得して回答に反映するアーキテクチャです。
これにより、モデルがトレーニングしていない最新情報やドメイン固有情報にも対応できます。
AWSでは、Amazon Bedrockのナレッジベース・Amazon Kendraを使ってRAG構成を簡単に実装できます。これにより、
S3に保存した社内ドキュメントやFAQを基に、自然言語での問い合わせに対する高品質な応答が可能になります。
生成AIの代表的なユースケース一覧
生成AIはさまざまな業務やプロダクトに応用可能です。以下はユースケースのカテゴリと具体例です。
| カテゴリ | 具体的なユースケース |
|---|---|
| 文章生成 | 記事作成、レポート自動生成、商品説明文の作成 |
| 要約・翻訳 | 議事録要約、多言語翻訳、長文の要点抽出 |
| コード生成 | 自動コード補完、ユニットテスト生成、関数説明 |
| チャットボット | 顧客対応、FAQ対応、社内ヘルプデスク |
| 検索支援(RAG) | 社内ドキュメント検索、カスタマーサポートの精度向上 |
| 画像生成 | 商品イメージの自動作成、デザイン案の生成 |
| 音声生成 | ナレーション音声作成、対話エージェント |
要件別利用サービス一覧
要件別にどのサービスをどう利用するのがよいか一覧化してみました。
その他の要件と組み合わせて回答の選択肢を絞ってみてください。
専門スキルを保有するメンバーがいない
- SageMaker Canvas:Canvasではノーコードでデータ分析・予測ができ、専門知識がなくても利用可能
- Bedrock:BedrockではAPIベースで基盤モデルを簡単に利用可能
数週間~1か月の短期間でサービスリリースしたい
- SageMaker Canvas:Canvasではノーコードでデータ分析・予測ができ、専門知識がなくても利用可能
- Bedrock:BedrockではAPIベースで基盤モデルを簡単に利用可能
運用中のモデルの動作が正常か確認したい
- SageMaker Model Monitor:デプロイされたモデルに対して、入力データ・予測結果・概念ドリフトのモニタリングを自動化し、正常動作を確認可能
モデルにバイアスがないか確認したい
- Amazon SageMaker Clarify:訓練データや推論結果のバイアス検出を行い、公平性・透明性を可視化することでAI倫理を担保する
法的要件で社内のデータの学習ができない
- Bedrock + RAG構成:基盤モデルには社内データを直接学習させず、ナレッジベースや外部検索を使って安全に情報を生成。RAGでコンテキストを制御
- Bedrock + プロンプトテンプレート:社内データをアップロードできない場合は、汎用的な形式でプロンプトテンプレート記載
利用頻度を予測できず従量課金制の生成AIを構築したい
- Bedrock(オンデマンド利用):使用したトークン数に基づいた従量課金モデルで、コスト管理しやすく、使用量に応じて柔軟にスケール可能。
AWSの基本サービス
AWSの基本サービスで押さえておくべき内容についてまとめました。
ネットワーク
コンプライアンスの制約上、通信をインターネットを経由せずにAWSのサービスを利用する方法について把握しておきましょう。
専用のVPCを作成し、サービスごとのVPCエンドポイントを配備することで、インターネットを経由せずにAWSサービスを利用することができます。
権限
IAMを利用して権限管理をします。必要な権限をIAMポリシーで定義し、IAMロールやIAMグループにアタッチして権限管理をします。
必要なサービスだけ利用できるようにIAMを使って権限管理をしましょう。
操作ログの管理
AWS管理コンソールの操作・AWS CLI・AWS SDKなどの操作はCloudTrailに記録されます。
CloudTrailでは90日間の操作ログを管理していますが、それ以上の期間のログを保管する場合は、S3やCloudWatchに出力する必要があります。
利用用途に応じて管理場所を決めますが、費用面ではS3で保管するほうがコストが安くできます。
試験の流れについて
試験まで
試験開始の15~30分前には会場に到着するようにしましょう。
これまでに受験したAWSの試験会場すべてで待合室での勉強は許可されていなかったので、ご注意ください。
早く着いてしまった場合でも席空いていれば早めに受験ができました。
遅れてしまった場合でも、諦めないこと!受付に相談すれば空き次第で受験可能な場合があります。
試験のポイント:
- 間違えてもペナルティはないので、分からない問題も必ず回答する。
- 分からない問題/違和感がある問題(おそらく採点対象外の問題?)はささっと回答して、できる問題から優先的に解く。考え込むと意外と時間が足りなくなります。
試験中
試験は約40分で1周できました。
AI・MLの用語やAWSの各種サービスの概要を押さえておくことで問題はスムーズに解けました。
Foundationalレベルの資格であるため、他の上位資格に比べて難易度はやや低めに感じました。
合格発表
試験直後の画面では合格したかどうかは分かりません。
※公式には5営業日以内に通知とあります
最速で結果確認したい場合は、試験当日の20時過ぎに「Skill Builder」で合格状況が分かります。
学習をしてみて
学習を通して、AI・MLの基本知識を身につけることができました。
一方で、「AWS Certified AI Practitioner(AIF)」を取得して、実践でAWSでAI・MLを利用するというのはハードルが高いと感じています。
まずはAI・MLを利用する上での第一歩として資格取得にチャレンジしてみてください。
まとめ
AWS Certified AI Practitioner(AIF)はAWSでAI・MLを利用する上での第一歩となる資格であり、学習の過程で、AI・MLの基本知識を学ぶことができます。
こちらであげた学習のポイントが皆様のスキルアップ、資格取得に貢献できると幸いです。
座学の後は、問題集を使って知識のブラッシュアップをしてみてください。
AIFは新しい認定資格ということもあり、問題集が少ない状況です。
Udemyには何件か試験対策用の問題集がありましたので、こちらを利用して本番形式でテストをしてみてください!